Hier, je me suis mis en tête d’essayer d’analyser le contenu de tous les textes adoptés par l’Assemblée nationale sous la législature actuelle (la quatorzième de la Vème République) pour voir comment les questions relatives au numérique y sont traitées. C’est un vaste sujet et si cette analyse se révèle fructueuse, je ne manquerai pas d’écrire un petit billet à ce sujet.
Là n’est pas mon propos aujourd’hui. Pour me livrer à cet exercice, il m’a fallu télécharger tous les textes adoptés. J’ai utilisé pour cela une astuce que j’utilise tous les jours et même plusieurs fois par jour : générer des commandes shell avec un script quelconque puis les faire exécuter en utilisant le pipe (|).
Télécharger les textes adoptés
Les textes adoptés sont tous listés sur une page dédiée du site de l’Assemblée nationale, dans l’ordre antéchronologique, 150 par page. Je suis naturellement trop paresseux pour tous les télécharger un par un. J’ai voulu faire un script.
Pour commencer, je voulais récupérer chacun de ces textes sous la forme d’un fichier texte. Un outil bien adapté pour ce travail est le navigateur web en mode texte lynx, dans les Linux modernes, il est remplacé par une version plus récente appelée links (voir links2). Ce navigateur permet de surfer sur le web en mode texte, ce qui peut être utile dans certains cas ; surtout, il propose une option -dump qui envoie le contenu de la page sur la sortie standard, c’est-à-dire généralement l’écran.
Ainsi, si vous tapez dans un terminal :
$ links2 http://liltools.lacherez.info
vous verrez ce blog dans une version texte. Pour naviguer, sachez que <flèche vers le bas> vous permet de passer de lien en lien, <flèche vers la droite> de suivre un lien et q de sortir.
Si, en revanche vous saisissez :
$ links2 -dump http://liltools.lacherez.info
tout le contenu de la page s’affichera sous forme de texte (j’insiste sur ce point : c’est du texte que vous voyez et non du HTML).
Il suffit alors de rediriger la sortie standard vers un fichier pour que le contenu de la page soit stocké dans ce fichier sous forme de texte :
links2 -dump http://liltools.lacherez.info > liltools.txt
Pour en revenir à l’Assemblée nationale, la commande
$ links2 -dump http://www2.assemblee-nationale.fr/documents/notice/14/ta/ta0811/(index)/ta > 0811.txt
écrira le texte adopté numéro 811 dans un fichier 0811.txt.
Tout cela est bel et bon, mais, me direz-vous, je n’ai aucune envie de répéter cette opération plus de 800 fois… C’est précisément pour cette raison que vous êtes sur ce blog  .
.
Je vais donc écrire un minuscule morceau de python pour écrire ces 800 et quelques commandes :
Il y a 828 textes au moment où je fais cette opération. Ils sont numérotés de 1 à 828 et dans l’adresse leur numéro est noté sur quatre chiffres.
Je fais donc une boucle de 828 itérations (en python range(1, 829) renvoie une liste des nombres de 1 à 828, c’est un peu étrange, mais il suffit de le savoir).
Je formate chaque nombre de façon à avoir une chaîne de 4 caractères, en complétant avec des 0 le cas échéant :
numero = "{:0>4}".format(a)Je place ce numero au bon endroit de l’adresse (identifié par %s) :
url = "http://www2.assemblee-nationale.fr/documents/notice/14/ta/ta%s/(index)/ta" % numero
Il ne me reste plus qu’à écrire ma commande avec links2 :
print("links2 -dump '%s' > %s.txt\necho %s" % (url, numero, numero))Naturellement, je redirige la sortie de la commande vers un fichier portant le même numéro et une extension .txt et pour ne pas m’impatienter, j’ajoute echo et le numéro, de façon à toujours savoir où j’en suis de mon téléchargement.
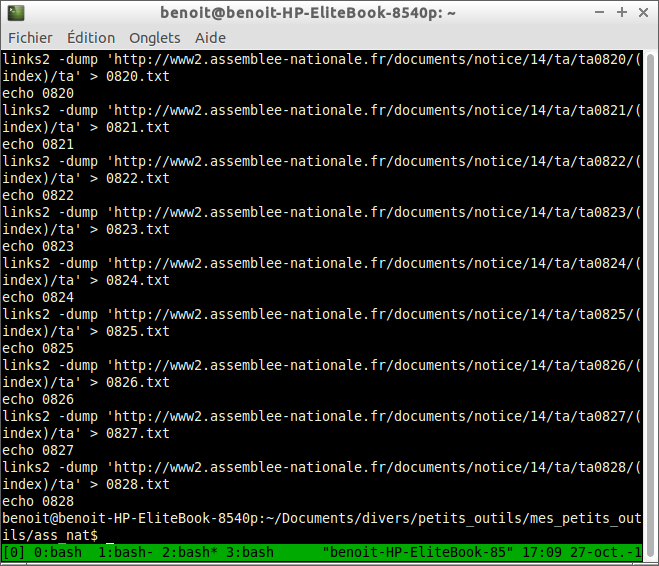
Quand je lance mon script, (python3 recupere.py) j’obtiens donc, pour chaque numéro, deux lignes de la forme :
links2 -dump 'http://www2.assemblee-nationale.fr/documents/notice/14/ta/ta0820/(index)/ta' > 0820.txt echo 0820
C’est là qu’arrive le pipe : je passe ces lignes à un shell :
python3 recupere.py | sh
Et là, devant vos yeux ébahis, tous les fichiers se téléchargent automatiquement !
Quel est l’intérêt du pipe ?
Evidemment, j’aurais pu utiliser d’autres fonctions en python pour télécharger les fichiers, sans passer par le shell.
L’avantage de ce système est que d’abord, il est facile à déboguer : je commence par afficher toutes mes commandes avant de les exécuter, il est facile de bien vérifier qu’elles correspondent bien à ce que j’attends.
La logique est très simple à suivre (j’ai toutes les commandes les unes après les autres) et je peux facilement reprendre n’importe où si la démarche a été arrêtée en cours pour une raison quelconque.
En outre, je peux utiliser simplement des outils unix classiques, sans être obligé de les récrire à partir de rien (je n’ai pas envie de recréer grep ou links, puisqu’ils existent déjà et qu’ils sont bien meilleurs que ce que je ferai jamais).