Quel CMS pour un site éco-responsable ? – Deuxième partie : le côté serveur
Après avoir évoqué le côté client dans un précédent billet, parlons du pendant “serveur” de la consommation énergétique d’un site web. Comme je le disais dans mon billet précédent, on trouve beaucoup moins d’informations sur ce sujet, ce qui le rend beaucoup plus intéressant ! :)
Côté “serveur”
L’outil Websitecarbon prend en compte un autre aspect, qui relève du côté serveur : le choix de l’hébergeur. C’est évidemment un élément important pour le bilan carbone d’un site web (comment est produite l’électricité utilisée dans le datacenter qui héberge le site, notamment) mais il est à la fois très accessible, d’une certaine façon (il est relativement simple de changer d’hébergeur), et complètement hors du périmètre des actions possibles (si on considère que l’hébergeur est un donné, il n’y a plus de marge de manœuvre à ce niveau). Je n’en parlerai donc pas.
Un aspect qui n’est pas du tout pris en compte par les outils que nous avons évoqués, en revanche, est celui du coût de génération de la page avant transmission au client. Les CMS gèrent généralement les pages de façon dynamique et la génération des pages, à la volée, nécessite évidemment des opérations qui ont un coût en matière d’énergie.
Rappel concernant les sites web
Nous considérerons trois types de sites :
-
Sites statiques : chaque page du site est stockée sous la forme d’un fichier HTML, qui est simplement envoyé lorsqu’un utilisateur souhaite y accéder. La page est donc toujours la même (impossibilité de personnaliser ou de proposer des éléments dynamiques). Un des problèmes d’un tel site est que, puisque chaque page est autonome, il est difficile de maintenir une présentation homogène sur l’ensemble du site. Des programmes existent qui génère un site cohérent à partir de fichiers contenant uniquement le contenu ; les pages ainsi créées sont ensuite mises en ligne. Ces logiciels, appelés “générateurs de sites statiques”, sont de plus en plus utilisés pour répondre à certains besoins. Comme exemple de tels générateurs, on peut citer Hugo ou Jekyll (c’est cet outil que j’utilise pour faire le blog où vous lisez ces lignes).
-
Les CMS “classiques” (type Wordpress, Joomla, Drupal, Typo3…) : le contenu du site et les éléments de mise en forme et de configuration sont stockés dans une base de données. Lorsqu’un utilisateur accède à une partie du site, le logiciel récupère les différents éléments dans la base de données et génère la page HTML correspondante.
-
Les CMS “flat files” (par exemple Grav). Comme leur nom l’indique, ces CMS utilisent des fichiers plats (c’est-à-dire des fichiers textes) pour stocker leurs données (contenus, paramètres de présentation et de configuration). Lorsqu’un utilisateur accède à une partie de site, la page est générée comme dans le cas d’un CMS classique, mais les données sont récupérés dans des fichiers au lieu d’une base de données.
Comparaison entre les différents CMS concernant la consommation d’énergie
S’il paraît évident que les pages statiques consomment beaucoup moins d’énergie que les CMS (puisqu’il n’y a pas à générer la page HTML à chaque connexion), la différence entre les deux types de CMS ne va pas de soi. Certes on peut estimer que les CMS “flat” économisent l’énergie nécessaire à la base de données, mais ils doivent récupérer leurs données sur le disque lors de la génération de la page ; or les bases de données ont été créées précisément pour permettre une manipulation des données plus efficace en termes de ressources que la manipulation de fichiers texte.
Il n’est guère aisé de trouver des informations sur ce type de comparaisons dans la littérature. C’est la raison pour laquelle j’ai décidé de faire une petite expérience pour avoir une meilleure vision de ces questions. Bien sûr ce test devrait être approfondi et perfectionné pour être complètement probant, mais il est prévu pour donner des ordres de grandeur et ainsi estimer l’opportunité de poursuivre dans les différentes voies pour obtenir des sites web plus respectueux de l’environnement.
Comparaison expérimentale entre les différents types de sites
Description du protocole
Je vais utiliser le logiciel PowerAPI pour obtenir une évaluation de la consommation électrique du serveur web (j’utilise Apache 2.4.41) et du serveur de base de données (MySQL 8.0.25), sur un ordinateur portable tournant sous Ubuntu Mate 20.04.2 LTS dans trois scénarios :
- connexions au CMS Grav; installation de base, sans aucune personnalisation ni ajout de contenu ;
- connexions au CMS Wordpress, installation de base, sans aucune personnalisation ni ajout de contenu ;
- connexion sur une page statique, version statique de la page d’accueil du Wordpress (avec la fonction “Enregistrer sous” de Firefox) ;
- connexion sur une page statique, version statique de la page d’accueil du Grav (avec la fonction “Enregistrer sous” de Firefox).
Pour limiter d’éventuelles variations aléatoires, je vais simuler un grand nombe de connexions à chaque fois. A noter que ni Apache ni MySQL ne sont utilisées pour autre chose sur cette machine.
Au préalable, nous allons utiliser des cgroups. C’est ce qui permettra à PowerAPI d’estimer la consommation par processus.
-
Création des cgroups
-
Affectation des processes correspondants aux groupes
Ces opérations nécessitent des privilèges administrateur (root).
Pour chaque scénario, nous reprendrons les étapes suivantes :
-
Lancement des containers
dockerde PowerAPI (voir https://powerapi-ng.github.io/howto_monitor_process/deploy_sensor.html et https://powerapi-ng.github.io/howto_monitor_process/deploy_formula.html). Pour simplifier la manipulation des données collectées, nous créons des collections Mongodb spécifiques pour chaque scénario. -
Attente pendant un certain temps, pour être sûr de capturer les données dès le début du test.
-
Tests, avec le script
browser_selenium.py
Dans un premier temps, j’avais utilisé l’outil ab (Apache benchmarking tool), mais un coup d’œil dans les logs du serveur Apache m’a révélé que cet outil envoie une seule requête pour l’url indiquée (donc typiquement, dans le cas qui nous intéresse, la page HTML), sans télécharger les fichiers annexes (images, fichiers CSS ou JS etc.). De même, les navigateurs texte (lynx, links, elinks etc.), qu’on peut également lancer en mode non interactif, ne chargent pas les fichiers annexes. J’ai donc décidé de faire un petit script en python, utilisant la bibliothèque Selenium qui permet de piloter un navigateur graphique (Firefox, Chrome etc.) de façon automatisée.
Ce script prend deux paramètres : un nombre de connexions et une url. Il se connecte une première fois à l’url indiquée, puis rafraîchit la page autant de fois que précisé dans le premier paramètre.
Il est important de noter que les résultats des tests sont très différents avec cette méthode et avec ab : les ordres de grandeur entre les différents scénarios testés ne sont absolument pas les mêmes et le classement des scénarios est également différent.
-
Attente pour être sûr qu’un délai dans le calcul ne risque pas de faire perdre des données.
-
Arrêt et suppression des containers
-
Exportation des données sous la forme d’un fichier CSV
Les commandes pour réaliser ces opérations sont rassemblées dans ce script sur Github.
En effet, comme je suis une grosse feignasse toujours soucieux que le travail que je fais une fois puisse être réutilisé, par moi ou par d’autres, j’ai écrit des petits scripts bash pour lancer ces tests de façon automatisée. Ils peuvent être récupérés sur Github. Il s’agit de trois scripts principaux et d’un autre par scénario :
-
env.shdéfinit des variables d’environnement communes à tous les scénarios, comme les paramètres de connexion à MongoDB, les caractéristiques du processeur etc., maus aussi le temps d’attente entre le démarrage des containers et le lancement des tests, le temps d’attente après les tests, le nombre de requêtes à envoyer. -
script_test.shest le fichier qui contient les principales commandes du test pour un scénario donné. Les paramètres liés au scénario étant fournis par des variables d’environnement affectée dansenv.shet dans le fichierenv_XXX.shpropre au scénario courant. -
cid.shlance les opérations communes à un ensemble de tests (création des cgroups etc., affectation des variables d’environnement globales etc.) puis lancescript_test.shpour chaque scénario. -
`env_XXX.sh définit pour chaque scénario (XXX étant un nom donné au scénario) des variables correspondant à ce scénario
Résultats des tests
NB : la consommation électrique estimée par PowerAPI est exprimée en Watts.
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
Grav
# On lit le fichier de données pour Grav
grav_csv = pd.read_csv("data_grav_selenium8.csv", parse_dates=["timestamp"])
data_grav = grav_csv[grav_csv['target'] == "/apache"] # On ne conserve que les données mesurées pour Apache
data_grav.head() # Aperçu des données collectées
| timestamp | power | target | |
|---|---|---|---|
| 26 | 2021-05-22 21:28:00.452000+00:00 | 0.000877 | /apache |
| 37 | 2021-05-22 21:28:01.460000+00:00 | 0.001058 | /apache |
| 42 | 2021-05-22 21:28:02.467000+00:00 | 0.001059 | /apache |
| 47 | 2021-05-22 21:28:03.475000+00:00 | 0.001596 | /apache |
| 54 | 2021-05-22 21:28:04.483000+00:00 | 0.000999 | /apache |
data_grav.describe()
| power | |
|---|---|
| count | 167.000000 |
| mean | 7.781255 |
| std | 7.342230 |
| min | 0.000877 |
| 25% | 0.002096 |
| 50% | 11.903439 |
| 75% | 14.494355 |
| max | 18.578162 |
data_grav.groupby("timestamp").sum().power.plot(x="timestamp")
<AxesSubplot:xlabel='timestamp'>
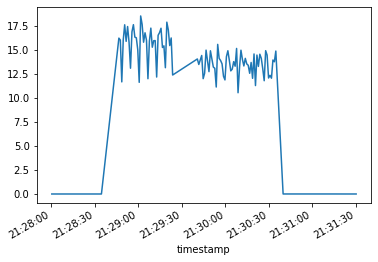
data_grav.power.sum() # Total de la consommation estimée sur la durée du test
1299.4695065483363
Wordpress
wp_csv = pd.read_csv("data_wp_selenium8.csv", parse_dates=["timestamp"])
data_wp_multi = wp_csv[(wp_csv['target'] == "/apache") | (wp_csv["target"] == "/mysql")] # Pour Wordpress, on conserve à la fois les données liées à Apache et celles liées à MySQL
data_wp_multi.head()
| timestamp | power | target | |
|---|---|---|---|
| 28 | 2021-05-22 21:24:26.661000+00:00 | 0.000000 | /mysql |
| 29 | 2021-05-22 21:24:26.661000+00:00 | 0.001558 | /apache |
| 36 | 2021-05-22 21:24:28.677000+00:00 | 0.000000 | /mysql |
| 37 | 2021-05-22 21:24:28.677000+00:00 | 0.002609 | /apache |
| 44 | 2021-05-22 21:24:30.693000+00:00 | 0.000000 | /mysql |
data_wp = data_wp_multi.groupby("timestamp").sum() # On rassemble les données d'Apache et de MySQL en les additionnant (consommation totale pour un timestamp donné)
data_wp.describe()
| power | |
|---|---|
| count | 139.000000 |
| mean | 7.306312 |
| std | 8.200727 |
| min | 0.001448 |
| 25% | 0.002615 |
| 50% | 0.003782 |
| 75% | 15.811131 |
| max | 18.882866 |
data_wp.power.plot(x="timestamp", xticks=[])
<AxesSubplot:xlabel='timestamp'>
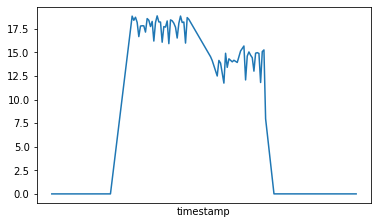
data_wp.power.sum() # Total de la consommation estimée sur la durée du test
1015.5773749500995
Site statique version 1 (page d’accueil de Wordpress traitée comme un site statique)
statique1_csv = pd.read_csv("data_statique_selenium8.csv", parse_dates=["timestamp"])
data_statique1 = statique1_csv[statique1_csv['target'] == "/apache"]
data_statique1.head()
| timestamp | power | target | |
|---|---|---|---|
| 22 | 2021-05-22 21:21:07.680000+00:00 | 0.001294 | /apache |
| 30 | 2021-05-22 21:21:09.693000+00:00 | 0.001758 | /apache |
| 38 | 2021-05-22 21:21:11.706000+00:00 | 0.001916 | /apache |
| 46 | 2021-05-22 21:21:12.714000+00:00 | 0.002152 | /apache |
| 61 | 2021-05-22 21:21:18.751000+00:00 | 0.002824 | /apache |
data_statique1.describe()
| power | |
|---|---|
| count | 120.000000 |
| mean | 4.955158 |
| std | 6.507998 |
| min | 0.001235 |
| 25% | 0.002489 |
| 50% | 0.002866 |
| 75% | 12.374628 |
| max | 16.355928 |
data_statique1.groupby("timestamp").sum().power.plot(x="timestamp")
<AxesSubplot:xlabel='timestamp'>
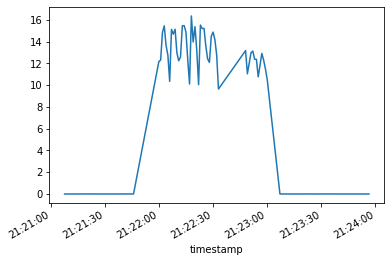
data_statique1.power.sum() # Total de la consommation estimée sur la durée du test
594.6189199028104
Site statique version 2 (page d’accueil de Grav traitée comme un site statique)
statique2_csv = pd.read_csv("data_statique2_selenium8.csv", parse_dates=["timestamp"])
data_statique2 = statique2_csv[statique2_csv['target'] == "/apache"]
data_statique2.head()
| timestamp | power | target | |
|---|---|---|---|
| 25 | 2021-05-22 21:31:57.557000+00:00 | 0.000711 | /apache |
| 30 | 2021-05-22 21:31:58.564000+00:00 | 0.000638 | /apache |
| 39 | 2021-05-22 21:32:00.578000+00:00 | 0.000663 | /apache |
| 46 | 2021-05-22 21:32:01.586000+00:00 | 0.000707 | /apache |
| 55 | 2021-05-22 21:32:02.592000+00:00 | 0.000796 | /apache |
data_statique2.describe()
| power | |
|---|---|
| count | 156.000000 |
| mean | 5.425120 |
| std | 5.509485 |
| min | 0.000638 |
| 25% | 0.000725 |
| 50% | 6.404217 |
| 75% | 9.823614 |
| max | 15.600828 |
data_statique2.groupby("timestamp").sum().power.plot(x="timestamp")
<AxesSubplot:xlabel='timestamp'>
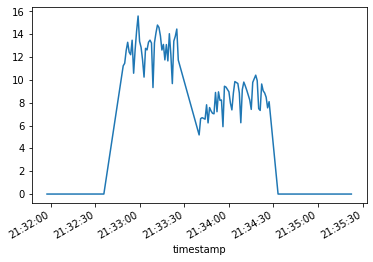
data_statique2.power.sum() # Total de la consommation estimée sur la durée du test
846.3186456889073
Discussion
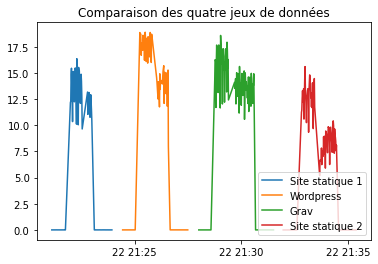
plt.title('Comparaison des quatre jeux de données')
plt.plot(data_statique1.timestamp, data_statique1.power)
plt.plot(data_wp.index, data_wp.power)
plt.plot(data_grav.timestamp, data_grav.power)
plt.plot(data_statique2.timestamp, data_statique2.power)
plt.legend(["Site statique 1", "Wordpress", "Grav", "Site statique 2"], loc="lower right")
<matplotlib.legend.Legend at 0x7fef21da3110>
# Comparaison Wordpress/Grav
data_wp.power.sum() / data_grav.power.sum()
0.7815322867003521
# Comparaison Wordpress/site statique 1 (même contenu de page)
data_wp.power.sum() / data_statique1.power.sum()
1.707946620864493
# Comparaison Grav/site statique 2 (même contenu de page)
data_grav.power.sum() / data_statique2.power.sum()
1.5354376429820498
# Comparaison Site statique 1 / site statique 2
data_statique1.power.sum() / data_statique2.power.sum()
0.7025946112989013
Première remarque importante : la consommation de contenus statiques n’est pas démesurément moins coûteuse que celle de contenus dynamiques. Ce point est intéressant, car il va à l’encontre de l’a priori que j’avais. D’ailleurs, il faudrait approfondir cette question, car lors de mes tests avec ab (donc une seule requête sur la page principale, sans requête sur les fichiers annexes), l’ordre de grandeur était incomparablement plus élevé : la consommation estimée pour une page statique était souvent plus de 1000 fois supérieure à celle pour une page générée (par Wordpress ou Grav). Une hypothèse pourrait donc être que le plus coûteux n’est pas tant le traitement de la page que le transfert des fichiers annexes. Cette information pourrait converger avec un des principes que nous avons évoqués dans la partie client : réduire autant que possible le volume des fichiers annexes (compression, “minification”, utilisation d’un nombre de fichiers limité etc.). C’est une hypothèse qu’il faudra approfondir.
Autre remarque : contrairement à une de nos hypothèses, la consommation électrique d’un CMS avec une base de données (Wordpress dans nos tests) n’est pas forcément moins économe que celle d’un CMS “flat”. Dans nos tests, c’est même le contraire, même si la différence est somme toute assez modeste. Là aussi il faudrait chercher la raison de cet état de faits. Une possibilité pourrait être liée à la structure de la page générée en elle-même ; en effet, on voit que le rapport entre les deux CMS est assez proche du rapport entre les deux sites statiques. En tout cas, il ne peut s’agir du simple poids des fichiers, car la version statique du site Wordpress (page HTML et fichiers annexes) pèse environ 260 ko, quand celle du site Grav est de 240 ko. La présence de deux fichiers supplémentaires dans le cas de Grav peut-elle expliquer la différence ? Encore un point qu’il faudra approfondir.
Je veux également reproduire les mêms tests en utilisant une page avec du contenu, pour vérifier que les échelles de grandeurs restent les mêmes et que la montée en volume de contenu servi n’induit pas des comportements différents.
Conclusion
En conclusion, il semble que l’optimisation côté client, même si elle n’est pas entièrement accessible à l’utilisateur d’un CMS, soit un investissement intéressant, en raison de la relation linéaire qui existe forcément entre la consommation d’énergie et le nombre de pages vues. Un soin particulier doit donc être apporté au choix des thèmes graphiques utilisés et à la configuration des médias, et plus généralement à toutes les bonnes pratiques évoquées dans mon billet précédent (pour autant qu’elles soient à la portée de l’utilisateur). La plupart de ces opérations relèvent plus d’une “hygiène numérique” que de véritables interventions techniques, et c’est le plus souvent par manque de temps ou par oubli que les utilisateurs ne les mettent pas en œuvre que par ignorance. Cette démarche, visible des clients, joue également un rôle en termes d’exemplarité par rapport aux internautes.
Côté serveur, le choix d’un hébergeur écoresponsable, même s’il n’entre pas dans le cadre de ce document, est sans doute le choix le plus efficace concernant le bilan carbone du site. Naturellement, un hébergement en France est un bon choix pour le strict bilan carbone, la majorité de l’électricité français étant produite avec du nucléaire donc peu émettrice de CO2.
En revanche, le changement de CMS promet des gains pour le moins aléatoires. Le coût d’une éventuelle migration devrait être pris en compte dans l’analyse (coût énergétique de la recréation d’un site avec un nouveau CMS, formations éventuelles etc.), de même que le nombre de pages vues du site. Contrairement à l’optimisation côté client, les efforts ainsi déployés ne sont pas directement visibles par l’utilisateur final et les économies constatées risquent fort de ne pas être à la hauteur des efforts consentis.
Le choix qui pourrait avoir un effet plus visible sur la consommation serait l’utilisation d’un générateur de sites statiques. Toutefois, les économies constatées lors de mes tests ne plaident guère en faveur de cette solution : la perspective est une réduction de la consommation qui ne serait même pas réduite de moitié. Là encore, il faut prendre en compte le coût énergétique d’une migration. Je dois avouer que je suis surpris de ce résultat (et un peu déçu, il faut bien le dire).
Surtout, le passage de Wordpress à Grav est à peu près indolore pour les contributeurs et les administrateurs : on reste sur une application web, avec une adresse pour l’édition et une adresse pour la consultation. En revanche, le passage à un générateur de site statique est de nature à perturber les workflows d’une façon beaucoup plus profonde : quel éditeur ? Local ou en ligne ? Comment synchronise-t-on les fichiers ? Comment gère-t-on les accès concurrents ? Comment et par qui le site statique est-il généré ? Pour ce blog, je modifie les fichiers markdown avec Atom, puis je les envoie sur un dépôt git sur Github (vous pouvez le consulter, il est ici). L’hébergeur de ce blog, Netlify, qui est spécialisé dans ce genre de sites, détecte automatiquement quand un fichier est mis à jour sur ce dépôt et lance alors la reconstruction du site. La mise en place d’un tel système pour une institution poserait un certain nombre de questions : le choix de Netlify est-il éco-responsable (selon la société, oui) ? Est-ce un choix responsable en matière de stockage de données ? Si on choisit de ne pas utiliser cet hébergeur ou un autre équivalent, quel workflow mettre en place ? Git est un outil bien connu des développeur, mais son utilisation par d’autres utilisateurs peut être complexe, La mise en place des workflows pour appliquer les changements au site en production peut aussi être complexe pour les administrateurs système, qui n’ont pas forcément l’expérience de ce fonctionnement (CI/CD, continuous integration/continuous deployment).
Cependant, un tel changement peut être utilisé pour communiquer, en interne et en externe, et notamment inciter les producteurs de contenu à une plus grande sobriété et donc à appliquer avec plus d’efficacité les pratiques de l’optimisation client. En externe, il permet de mettre en avant l’exemplarité de l’acteur impliqué et à sensibiliser les partenaires externes à ces questions de numérique responsable.
Si vous avez des informations complémentaires à ce sujet, ou si vous remarquez une erreur dans la façon dont j’ai réalisé mes tests, ou encore si vous avez des idées pour les améliorer, n’hésitez pas à me contacter (vous devriez trouver un moyen ici). De même, si vous faites des tests sur le même sujet ou si vous voulez de l’aide pour mettre les miens en œuvre sur votre machine, contactez-moi !